Threat Hunting with ML - Part 4 - T1053.005 / Scheduled Tasks Anomaly Detection with an Autoencoder
 | [27/05/21] May 27, 2021 Jess Garcia - One eSecurity Twitter: j3ssgarcia - LinkedIn: garciajess |
[ Full blog post series available here ]

Photo by Omid Armin on Unsplash
In previous parts of this blog post series we introduced our objective: trying to detect malicious activity through anomaly detection via machine learning. We also defined a specific use case: detecting the Solarwinds/Sunburst Campaign intrusion without IOCs, specifically via the detection of its malicious scheduled task. And to end up with, we also explained the forensic artifacts associated with scheduled tasks activity.
In this post we will introduce the Autoencoder, a neural network architecture which is very effective detecting anomalies.
What is an Autoencoder and How Does It Work?
As discussed in Part 1 of this blog post series, the Autoencoder model is one of the most efficient and convenient for Anomaly Detection. But, what is an Autoencoder?
An autoencoder is a type of artificial neural network used to learn efficient data codings in an unsupervised manner. The aim of an autoencoder is to learn a representation (encoding) for a set of data, typically for dimensionality reduction, by training the network to ignore signal “noise”. Along with the reduction side, a reconstructing side is learned, where the autoencoder tries to generate from the reduced encoding a representation as close as possible to its original input, hence its name.[ 1 ]
Or, to express it in a simpler more graphical way:
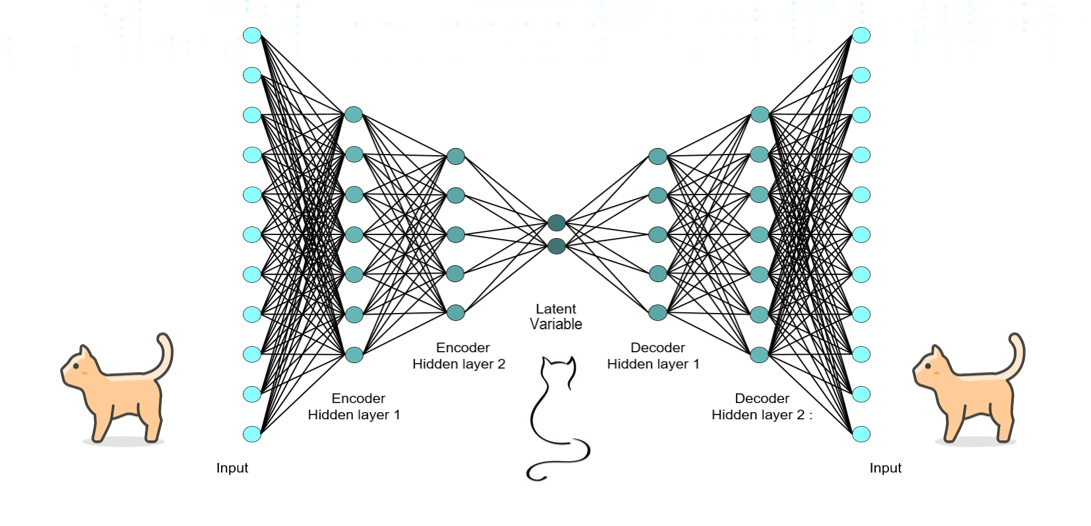
- The Autoencoder will read inputs of a certain type, let's say cats.
- By ignoring “noise” (i.e. minor cat details) it wil get to learn the “essence” of what a cat is in its middle layer.
- When you provide a specific entry (a specific cat) as input to the Autoencoder, by using that “cat essence” it will try to reproduce the original input cat in the output.
- The Autoencoder will provide you the error (loss or cost) of the operation, that is, how different the reconstructed cat is from the original cat.
- If the loss is low, this means that the model has been able to properly reconstruct the original input cat in the output by using the “cat essence”. In other words, the input cat is similar, in essence, to the cats the neural network has seen before.
- If the loss is high, this means that the model has not been able to properly reconstruct the original input cat in the output by using the “cat essence”. In other words, the input is different to the cats the neural network has seen before (it may be a strange type of cat that the network has not seen before or a not a cat at all).
The most useful thing for us is that the reconstruction error, the loss, is a value that we can use to differentiate how different (anomalous) each input object is.
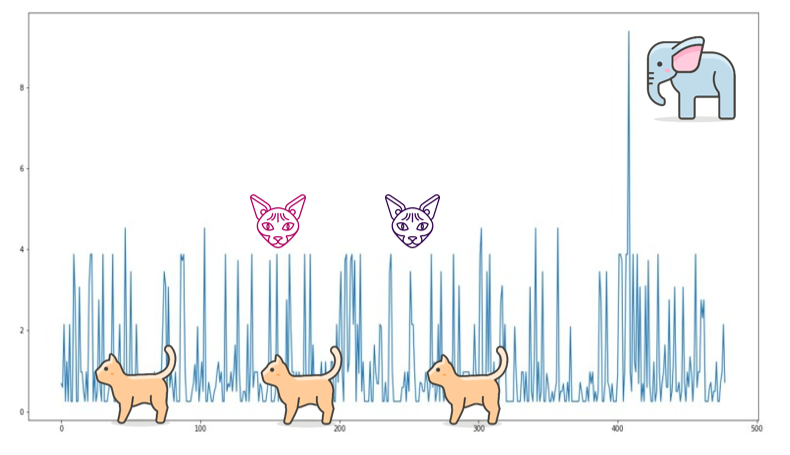
There is a loss value per input entry (per input cat), so:
- The “normal” objects (the most common cats), the ones the neural network is most familiar with, will have the lowest loss.
- The not-so-common objects (“strange” cats) will have a loss in the middle of the spectrum.
- The most anomalous entries (elephant) are the ones with the highest loss.
As a summary, an Autoencoder has the capability to detect anomalies in a dataset. For each input object we present to the Autoencoder, it will give us a measure of how anomalous it is (different than the rest of the objects it has seen before).
If, instead of finding anomalous cats what you want is to find anomalous Scheduled Tasks events, you would provide the different evtx fields as input:

The neural network will learn the “essence” of Scheduled Tasks events, and it will return the loss (reconstruction error) of each input event, in other words, how anomalous each event is when compared with the rest of the dataset previously presented to the neural network.
It is important to note that in this case you will not provide all the event logs, but only the “unique” event logs. That is, if there is an event log entry that repeats over and over again in the same system (e.g. the execution of an hourly scheduled task), it is just considered as a single entry. In other words, we are not taking into account the time variable in this analysis, only the event logs which are different from each other.
Why Is an Autoencoder Useful for Us?
Now that you've seen it in action, you can probably appreciate the characteristics that make the Autoencoder very useful for detecting anomalies:
- Unsupervised: An Autoencoder is an unsupervised Machine Learning model. This means that you don't need to train the model with tagged data (in our case good activity / malicious activity) before using it. This is very important for us because we don't normally have enough different incidents in our organization (or publicly available on the Internet) to teach our model what “malicious” looks like. Additionally, even if we had enough malicious data at hand, tagging every artifact entry (e.g. event log) as malicious or non-malicious is a dauting and time-consuming task.
- Anomaly Metrics: As you will see later, the Autoencoder returns a reconstruction error value that can be used as a metric of how anomalous each sample is when compared with the rest of the samples the Autoencoder has seen in the past.
- Simple: As you will see below, even when you can create very complicated Autoencoder architectures, a simple Autoencoder is pretty good at detecting anomalies. As you will also see in a later post, programming a standard Autoencoder is also pretty simple.
- Flexible: An Autoencoder architecture can be used together with other Machine Learning models / architectures (CNN, LSTM, …), allowing you to create anomaly detection mechanisms which can be adapted to many different use cases (see here).
Let's See It in Action!
Without further ado we will go straight to using the Autoencoder to process our Scheduled Tasks event logs. We will discuss later its benefits, and we will cover in a later post the gory details of how it works at the low level and how you code it.
What we will do now then is to just run the model with the input data and see how it performs in terms of detecting 3 increasingly anomalous Scheduled Tasks event log entries (that is, different from the rest of the event log entries presented to the Autoencoder).
We have created a function called find_anomalies() (which we will also explain and analyze in-depth in a later post) which hides all the complexity of the underlying Autoencoder Machine Learning process involved, and we will now apply it to our input data (i.e. our unique input event logs).
The find_anomalies() function is very simple: you provide your input data, that is, the Scheduled Tasks event logs (in the form of a pandas DataFrame), and you will get back the reconstruction error for each event log entry in the input. Or, in other words, how anomalous each event log entry is when compared with the rest of the event logs.
We will now show you how an Autoencoder works in a small demo video in which we will do the following:
- 1. First, we will present a “very unique” event to the Autoencoder, i.e. an event which is very different from the rest of the events of the dataset.

- 2. Then, we will present a “not-so-unique” event to the Autoencoder, i.e. an event which is quite different from the rest but not as unique as the previous one.

- 3. To end up with, we will present an “average” event to the Autoencoder, an event which is very similar to the rest of the events on the dataset.

Note: Some of the fields of the above events have been sanitized after running the prediction process because the data used in this whole process is real server data from a production environment. You may also notice an unfamiliar field, UserNC_, which is the result of merging 2 Scheduled Tasks event log fields to make predictions more accurete (this is called Feature Engineering and we will discuss it in a later post).
Take a couple of minutes to get familiar with how an Autoencoder works by watching this short demo video.
So out of 8.465 different event log entries in the dataset, the “anomaly order” in which they appear (0 → most anomalous / 8.464 → least anomalous) is:
- Very Unique → 20
- Not-so-unique → 271
- Average → 1.935
As you can see, the more unique the event is, the higher it appears in the anomaly classification. The Autoencoder behaves the way we expect it should.
We are now ready to use this Machine Learning model in our Solarwinds/Sunburst case study and see how it performs.
Stay Tuned and contact us if you have any comment or question!
[ Full blog post series available here ]